【初心者向け】BigQueryの基本的な使い方を実例で徹底解説!データ分析の第一歩を踏み出そう
技術ブログはじめに
データ分析初心者向けに、BigQueryを使った基礎を解説します。アカウント設定からSQLクエリ、データ読み込み、分析例に加え、コストとセキュリティ管理まで網羅し、ビジネス成長に役立てる知識を提供します。
BigQueryとは?クラウドデータウェアハウスの基礎知識
BigQueryの概要と特徴
BigQuery は Google Cloud ( Google が提供するパブリッククラウドサービス)に提供するフルマネージドのクラウド データウェアハウス サービス( DWH )です。なお、 DWH は日本語で「データの倉庫」と呼ばれている IT ツールで、膨大なデータを保管するための場所として利用されます。
BigQuery は様々な特徴を有したサービスであり、グローバルで多くのユーザーに支持されています。
例えば、SQL クエリで高速なデータ処理や高いコストパフォーマンス、使いやすいインターフェースなどが BigQuery の大きな特徴として挙げられます。
なぜBigQueryが選ばれるのか?導入メリット
BigQueryは、Google Cloudが提供するフルマネージドのエンタープライズデータウェアハウスです。従来のデータウェアハウスと比較して、以下のような優位性があります。
①優れたパフォーマンスとスケーラビリティ
数テラバイトからペタバイト級のデータに対して、わずか数秒でクエリを実行できます。これは、Googleのインフラストラクチャを基盤とする分散型アーキテクチャによって実現されており、データ量の増加に応じて自動的にリソースを拡張します。
②サーバーレス
インフラの管理(サーバーのプロビジョニングやパッチ適用など)が不要なため、運用の手間が大幅に削減され、エンジニアはデータ分析そのものに集中できます。
③費用対効果
ストレージとコンピューティングが分離されており、クエリ実行時のみ料金が発生する従量課金制です。
未使用時のコストを抑えられます。
④統合されたエコシステム
Google Cloud の他のサービス(Dataflow、Looker Studio、Vertex AIなど)と簡単に連携できます。これにより、データのETL(抽出、変換、ロード)、可視化、機械学習への応用など、幅広い用途に対応できます。
BigQueryの始め方|導入手順と環境構築のステップ
Google Cloudプロジェクトの作成とBigQueryの有効化
Google Cloud アカウントを作成したら、以下の手順でプロジェクトを作成します。
- Google Cloud コンソールにアクセスします。
- 左側のメニューから「 BigQuery 」を選択します。
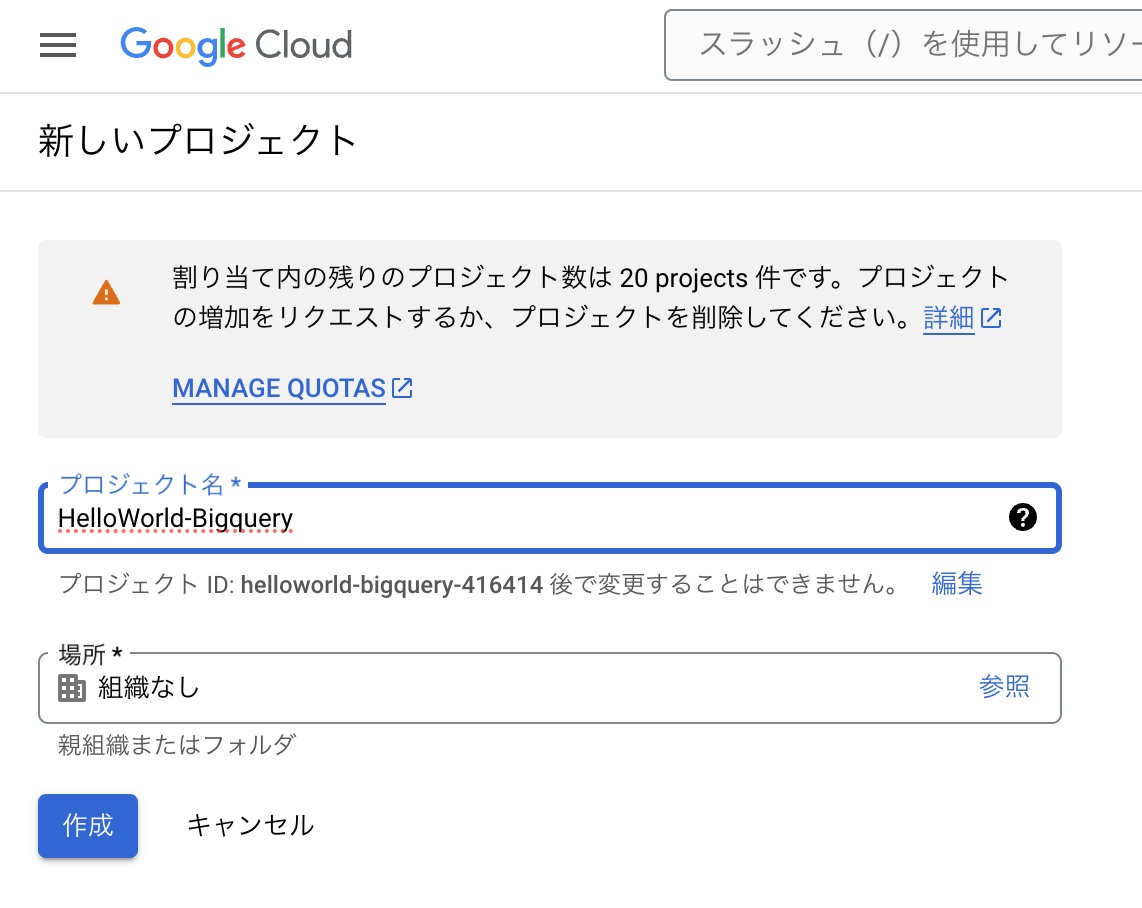
- 画面左上の「プロジェクトを作成」をクリックします。
- プロジェクト名と所在地を入力します。
- 「作成」をクリックします。
プロジェクト作成後、BigQuery API を有効にする必要があります。
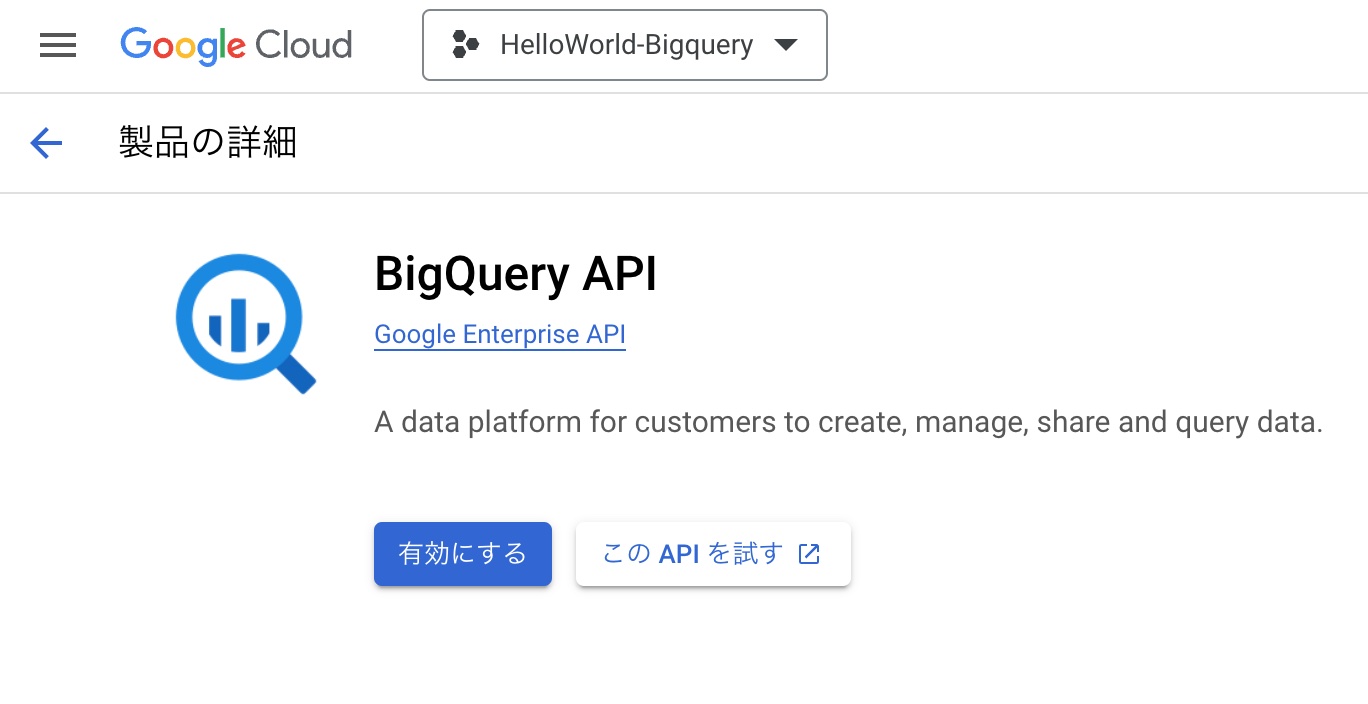
- Google Cloud コンソールで、左側のメニューから「 API とサービス」を選択します。
- 画面上部の検索バーに「 BigQuery 」と入力します。
- 検索結果から「 BigQuery API 」を選択します。
- 「有効にする」をクリックします。
データセットとテーブルの作成方法
BigQuery でのデータ分析を始めるためには、まず「データセット」というコンテナを作成し、その中に分析対象のデータを格納する「テーブル」を作成する必要があります。ここでは、それぞれの作成方法と、なぜそれらが必要なのかについて解説します。
データセットの作成
データセットは、関連するテーブルやビューをまとめて保管するためのコンテナです。プロジェクト内でデータを論理的に整理し、アクセス権を管理する際に重要な役割を果たします。データセットの作成手順は以下の通りです。
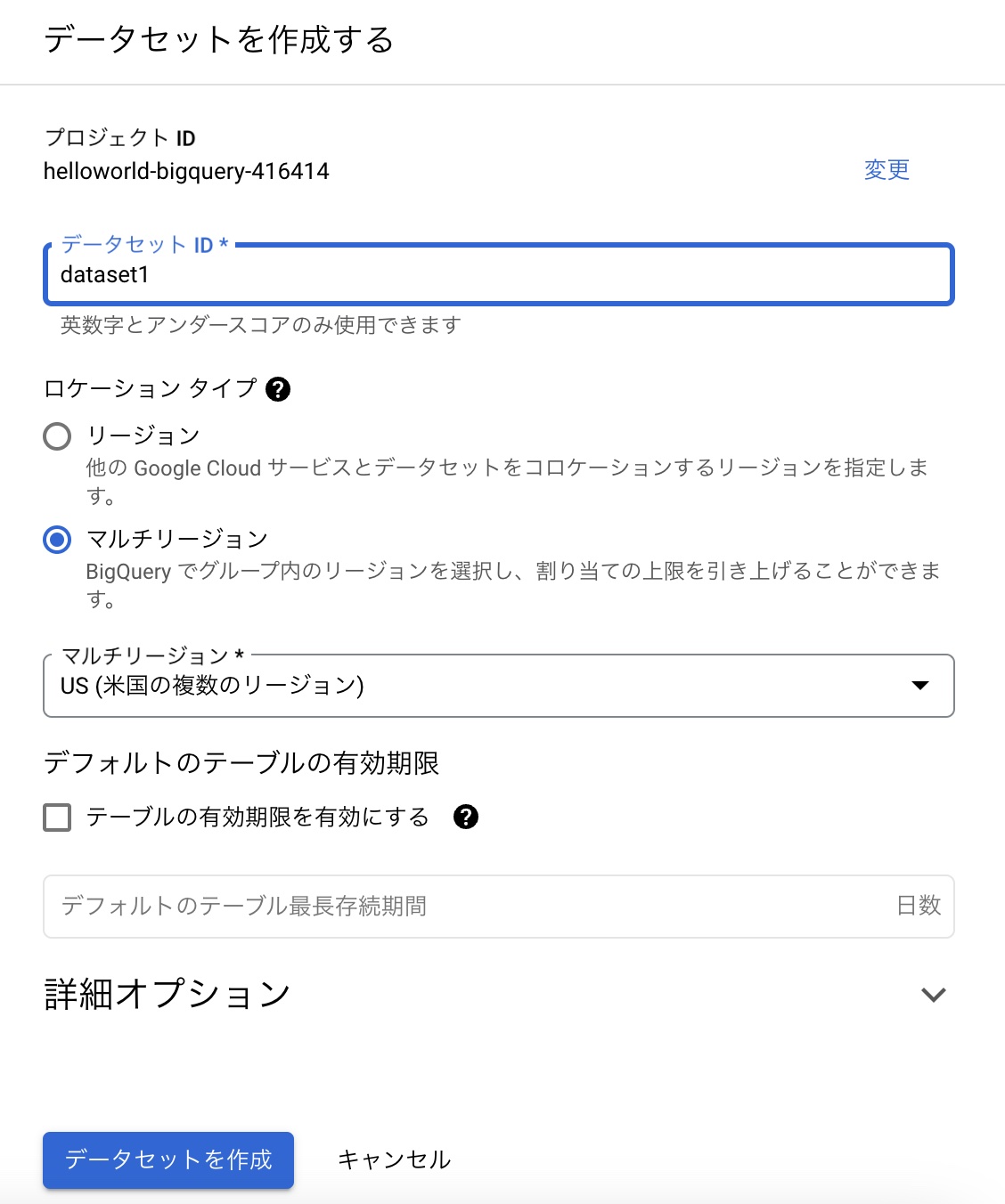
- BigQuery コンソールで、プロジェクトから「データセットを作成」をクリックします。
- データセット名とロケーションを入力します。
- 「データセットを作成」をクリックします。
テーブルの作成
テーブルは、データセット内に作成され、分析対象となるデータを実際に保持します。テーブルを作成することで、生のデータを構造化し、BigQuery で効率的に分析できるようになります。
テーブルの作成手順は以下の通りです。
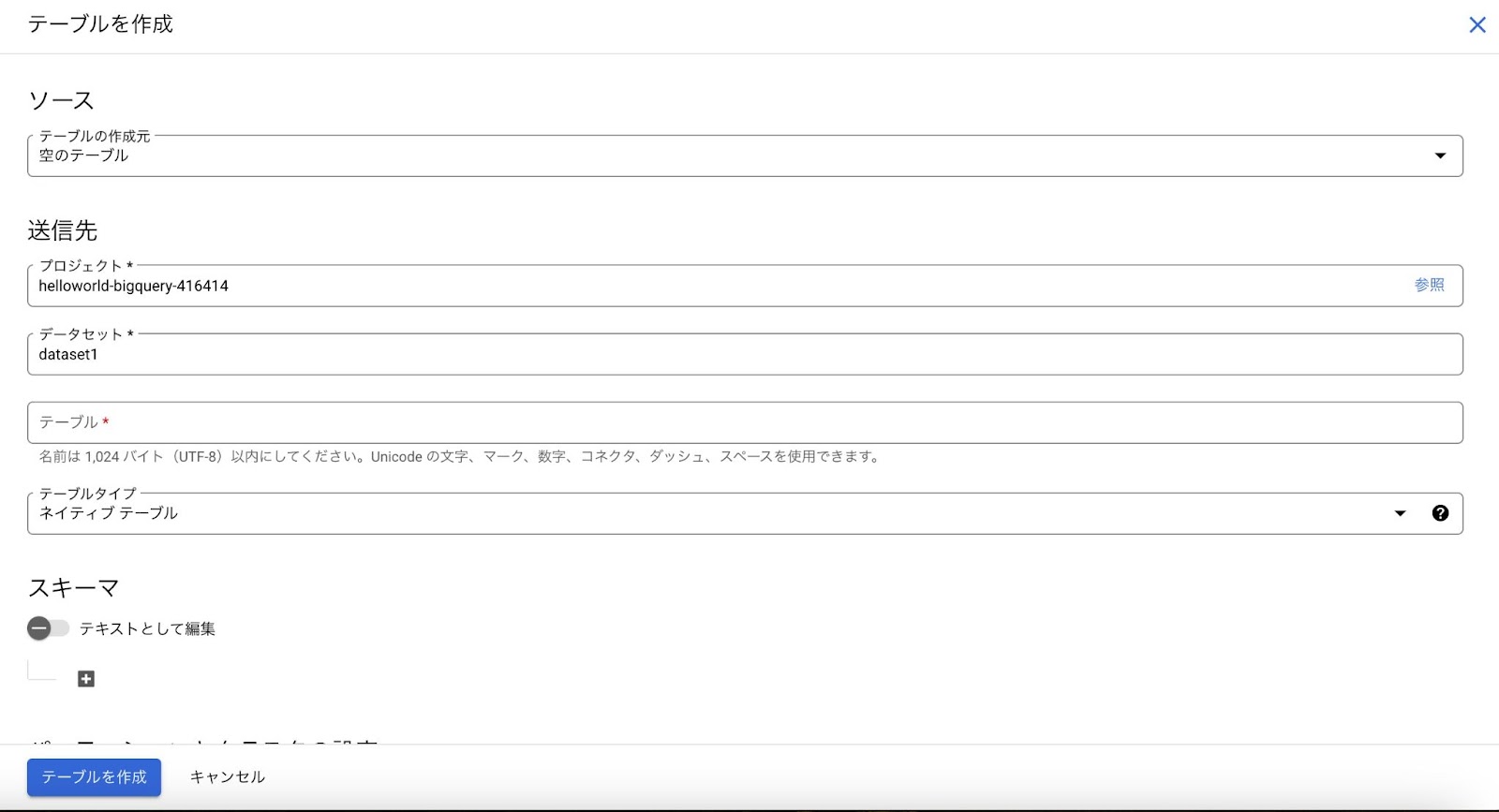
- データセットから「テーブルを作成」をクリックします。
- テーブル名、スキーマを入力します。
- 「テーブルを作成」をクリックします。
BigQueryの使い方|初心者向け実例とSQLサンプル集
データの読み込み(インポート)方法
- CSV、JSON など、さまざまな形式のデータをインポートできます。
- Web UI、コマンドラインツール、BigQuery API を使用してインポートできます。
SQLによるデータクエリの実行
BigQuery で使用される SQL は、標準的な SQL 文法に基づいていますが、ビッグデータを効率的に扱うための独自の機能も備えています。基本的な SELECT 文から始めて、データのフィルタリング、集計、そして結合まで、データ分析に必要な操作を網羅的にカバーします。
SQL 文例
SELECT name, age
FROM `project.dataset.table`
WHERE age >= 18
ORDER BY age DESC
LIMIT 10;
このクエリでは、特定のテーブルから名前と年齢を選択し、18歳以上のレコードのみをフィルタリングして、年齢の降順で上位10件を表示します。
その他の重要な文法:
- WHERE : 条件に基づいてレコードをフィルタリング
- GROUP BY : 特定の列に基づいてデータをグループ化
- ORDER BY : 結果を特定の列に基づいてソート
- JOIN : 複数のテーブルからデータを結合
データ分析のためのクエリ例
シナリオ: オンラインストアの販売データから、最も人気の商品カテゴリを特定する。
SQL 文例
SELECT product_category, COUNT(order_id) AS order_count
FROM `project.dataset.sales`
GROUP BY product_category
ORDER BY order_count DESC
LIMIT 5;
このクエリでは、商品カテゴリごとに注文数を集計し、最も注文数の多い上位5つのカテゴリを特定します。
その他の分析シナリオ:
- 特定の期間における顧客の購買傾向を分析
- 製品レビューから顧客の満足度を分析
- 異なるマーケティングキャンペーンの効果を比較
以上のようなシナリオでも、クエリを使うと簡単に実現できます。
クエリ結果のエクスポート方法
BigQuery は、CSV ファイルだけでなく、多様なデータソースからデータを柔軟に取り込むことができるデータ分析プラットフォームです。ここでは、CSV ファイルに加えて、Google Cloud Storage と Google スプレッドシートの3つのデータソースを例に、それぞれの読み込み方法を詳しく解説します。
①CSV ファイルからのデータソースの読み込み
CSV ファイルは、データ分析で最も一般的に使用されるデータ形式の一つです。カンマで区切られたシンプルな構造のため、多くのツールで簡単に扱えます。BigQuery では、以下の方法で CSV ファイルを簡単に読み込むことが可能です。
- 左側のナビゲーションメニューから データセット をクリックします。
- 作成したデータセット titanic_survival をクリックします。
- テーブルを作成 をクリックします。
- 以下の項目を入力します。
- テーブル名: titanic_passengers
- テーブルの作成元: アップロード
- ファイル形式: CSV
- ファイルの選択: ダウンロードした CSV ファイル
- スキーマ: 自動検出
「テーブルを作成」 をクリックします。

②Google Cloud Storage からのデータソースの読み込み
Google Cloud Storage は、Google Cloud が提供するオブジェクトストレージサービスです。大量のデータを安全かつスケーラブルに保存することができ、BigQuery とシームレスに連携できます。
Google Cloud Storage から読み込むには、以下の手順に従います。
- Google Cloud Storage バケットの作成
- CSV ファイルのアップロード
- BigQuery でのテーブル作成
BigQueryの活用術|費用削減と分析効率化のポイント
費用を抑えるためのポイント
クエリ実行時に処理されるデータ量に基づいて課金されますが、以下で述べたベストプラクティスを実践することにより、データ処理量を削減することができます。
①データの分割とパーティショニング
テーブルを論理的に分割することで不要なデータの読み込みを避け、コストを削減できます。さらに、時間や地域など分析に役立つ属性に基づいてパーティショニングを行うことで、クエリのパフォーマンスを向上させ、コストを削減することが可能です。
②必要なデータのみを対象にクエリを実行する
WHERE 句や LIMIT 句を活用して、必要なデータのみを抽出することで、データ処理量を削減できます。
③クエリのパフォーマンスを最適化する
不要な SELECT * を避け、必要な列のみを指定することでデータ処理量を削減することができます。また、集計操作の前に行単位でのフィルタリングを行うことにより、より効率的なデータ処理を実現できます。
まとめ:Google Cloudでデータ駆動型経営を加速する
Google Cloudは、BigQueryに代表される高いスケーラビリティとパフォーマンス、Vertex AIによるAI/MLとのシームレスな統合、そしてフルマネージドサービスによる運用負荷の軽減という点で、現代のデータ分析ニーズに最適なプラットフォームです。
データ分析基盤の構築やAI活用を検討されている方は、Google Cloudパートナーであるセンティリオンシステムにご相談ください。当社は、高度な技術力と豊富な導入実績に基づき、お客様のデータ分析戦略立案から、Google Cloud環境の構築、ツールの導入・運用まで、一気通貫でサポートいたします。



